Select with partially matching index: can we make it faster?
- Jun 20, 2024
- 10 min read
Let's assume we want to select a set of customer ledger entries based on two values: salesperson code and the payment reference. Or any subset of records from any other table that satisfies two criteria: the table is large enough, so the query can benefit from an index, and that index exists, but does not cover all of the fields which we are going to filter on.
Salesperson and payment reference in the customer ledger entry table is good illustration of this scenario: CLE is usually one of the largest tables in the Business Central database, and an existing index includes only the salesperson code with the payment reference not indexed.
How would we approach this task?
Normally, I would assume that I simply set filters on both fields and let SQL Server decide the best strategy to handle the request. If the query becomes too slow, I would consider adding another index that would include both fields. Something like this.
CustLedgerEntry.SetRange("Salesperson Code", SalespersonCode);
CustLedgerEntry.SetRange("Payment Reference", Reference);
if CustLedgerEntry.FindSet() then
repeat
DoSomething();
until CustLedgerEntry.Next() = 0;But once I came across a different pattern which never crossed my mind: select all rows filtered on the fields matching the existing index (salesperson in this example) to make use of the index as much as possible, and shift the rest of the filtering to the application side. Like this.
CustLedgerEntry.SetRange("Salesperson Code", SalespersonCode);
if CustLedgerEntry.FindSet() then
repeat
if CustLedgerEntry."Payment Reference" = Reference then
DoSomething();
until CustLedgerEntry.Next() = 0;
At first glance, this way we are helping SQL Server to fully utilize the index and find required rows without scanning the clustered index, which is likely to be the preferred execution plan if the query runs into a very active salesperson whose entries constitute a significant portion of the customer ledger entries.
But... on the other hand, the database engine still has to read all those rows that will be rejected by the client, which means reading index entries and performing an expensive key lookup operation on all of them. And then all these records must be sent to the BC server for filtering.
So my first impression was: no way this approach can be better than simple filtering on all fields that need to be filtered. But I have a habit of doubting myself, so I ran a few tests, which I will will describe below.
Spoiler: the first impression was correct. This shift of filtering from SQL Server to the application side does not help improve performance and generally not recommended, but if you want to understand why this doesn't work, this post will unveil some details under the hood.
Test tables and data
I did not actually run the tests on the Customer Ledger Entry table, but prepared a custom one instead. This custom table, which I called MyFactTable, has four code fields, one decimal, and an integer Entry No. as the primary key.
fields
{
field(1; "Entry No."; Integer)
{
Caption = 'Entry No.';
}
field(2; "Code Field 1"; Code[20])
{
Caption = 'Code Field 1';
}
field(3; "Code Field 2"; Code[20])
{
Caption = 'Code Field 2';
}
field(4; "Code Field 3"; Code[20])
{
Caption = 'Code Field 3';
}
field(5; "Code Field 4"; Code[20])
{
Caption = 'Code Field 4';
}
field(6; Amount; Decimal)
{
Caption = 'Amount';
}
}Besides the primary key on the Entry No. field, an additional index is declared on the combination of two code fields: Code Field 1", "Code Field 2.
keys
{
key(PK; "Entry No.")
{
Clustered = true;
}
key(CodeIndex; "Code Field 1", "Code Field 2") { }
}And the question I want to answer is which of the following two approaches described above is more efficient. Initially, I am excluding BC from tests and only want to analyze SQL queries generated by respective AL code. So I want to filter records from my table on both fields which are in the index, plus another filter on the additional non-indexed field Code Field 3. As the result of the query, I want to receive the last code value Code Field 4 and the Amount field.
MyFactTable.SetLoadFields("Code Field 4", Amount);
MyFactTable.SetRange("Code Field 1", CodeFilter1);
MyFactTable.SetRange("Code Field 2", CodeFilter2);
MyFactTable.SetRange("Code Field 3", CodeFilter3);
MyFactTable.FindSet();And after that, I test the alternative approach and filter the records on two indexed fields only, moving the Code Field 3 to the query output.
MyFactTable.SetLoadFields("Code Field 3", "Code Field 4", Amount);
MyFactTable.SetRange("Code Field 1", CodeFilter1);
MyFactTable.SetRange("Code Field 2", CodeFilter2);
MyFactTable.FindSet();Two queries that Business Central will generate from this code will differ in the output list and the search predicate highlighted below.
SELECT
"50100"."timestamp","50100"."Entry No_",
"50100"."Code Field 1","50100"."Code Field 2",
"50100"."Code Field 1","50100"."Code Field 3",
"50100"."Code Field 3","50100"."Code Field 4",
"50100"."Amount","50100"."$systemId","50100"."$systemCreatedAt",
"50100"."$systemCreatedBy","50100"."$systemModifiedAt",
"50100"."$systemModifiedBy"
FROM "CRONUS".dbo."CRONUS International Ltd_$MyFactTable$382b9cf1-7c89-48eb-bdc6-be609426126a" "50100" WITH(READUNCOMMITTED)
WHERE (
"50100"."Code Field 1"='4EE83D62-4766-463D-9' AND
"50100"."Code Field 2"='A24005CD-48F4-4756-9' AND
"50100"."Code Field 3"='2E221581-0095-4920-9')
ORDER BY "Entry No_" ASC OPTION(FAST 50)The first query has Code Field 3 in the WHERE clause, whilst the second moves it to the output instead.
Before I start running the queries, I need to generate the data that I will be querying. For all of the tests, I generate one million records in MyFactTable with different distribution in each test. And this is mainly what I want to test - what kind of execution plan will SQL Server produce for various data distributions and different search conditions. Values of Code fields are randomly selected from a prefilled dimension table MyDimTable containing 10000 unique records for each of the four dimensions. To be clear, these values are not BC dimensions, I just follow the naming convention for a star database schema with a fact table and dimension tables.
Test 1: uniformly distributed code values
For the first one, I assign all code values uniformly randomly - any of the 10000 values from the dimension table can be selected with equal probability. As a result, a few combinations of Code Field 1 and Code Field 2 are repeated more than once among the million fact records.
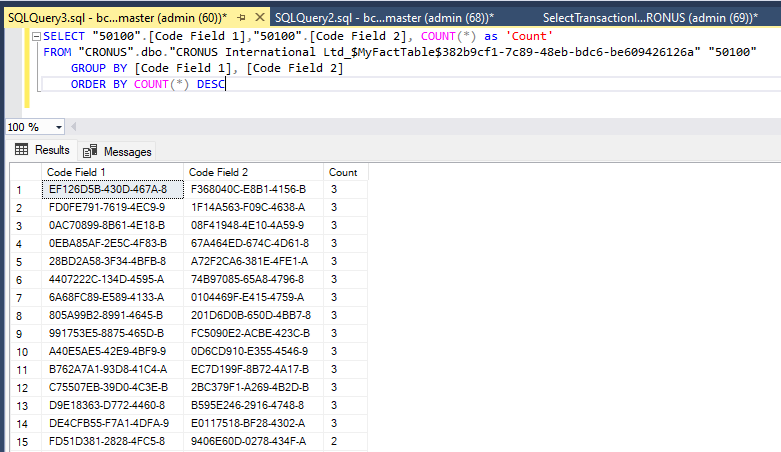
But when it comes to matching all three fields, each combination is unique and encountered in the table strictly once.

All tests are executed on a cold cache to prevent interference from previous runs, SQL Server is restarted before running each test. In each execution I include the actual execution plan and client statistics.
Let's start.
First I select entries from MyFactTable filtered on two code fields, then apply additional filter on the Code Field 3. For this test I selected the code values in a way that only one record satisfies the filters in both cases. And both times the execution plan SQL Server follows is exactly the same.
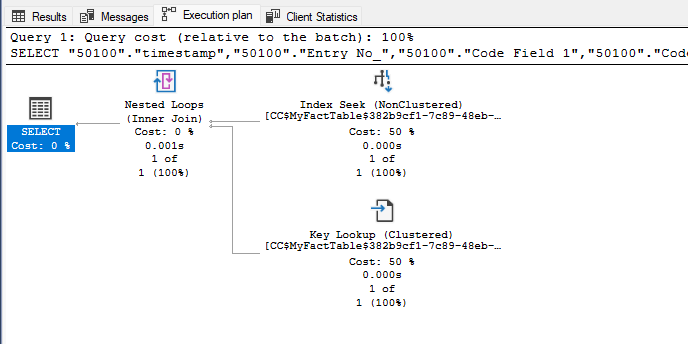
It doesn't matter if we filter on two or three fields, SQL Server query optimizer is able to estimate the benefit of the index and use it in both queries, even if it matches the search predicates only partially.
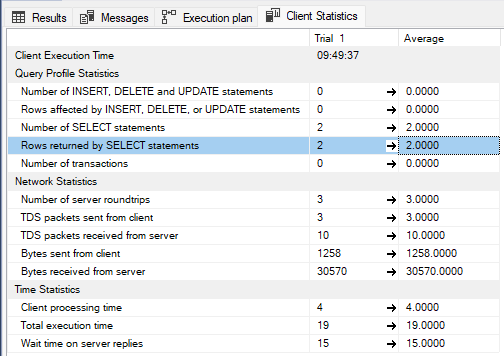
Client statistics also show practically identical results. Record retrieved based on two filters is returned and processed in 19 ms.
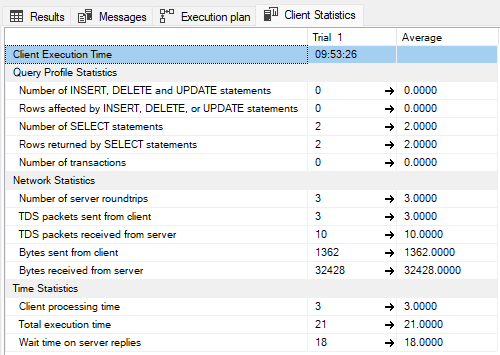
With 3 filters applied, it takes 21 ms - the difference within the error margin.
Test 2: Skewed data
So the first test on a uniformly distributed data set shows the same execution plan and little to no difference in the execution time between the two filtering methods. But this kind of distribution almost never happens in practice - usually the probability distribution is not uniform, and some values are more frequent than others. This distribution can change the execution plan that SQL Server chooses for the query. Besides, the volume of data sent back to the client will be different as well.
Test 2 explores another extreme - highly skewed data in all three filtered columns, such that 10% of the data now contains the same combination of Code Field 1, Code Field 2, and Code Field 3.
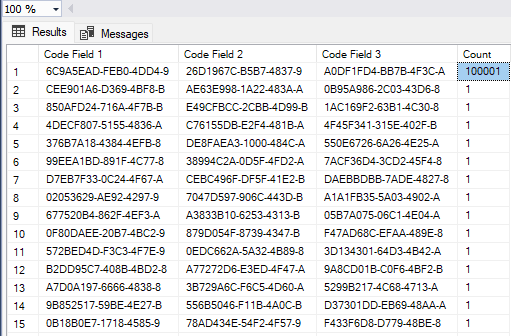
When I run the test this time, I want the query to return the whole cluster of 100 000 records, so I choose the filter values respectively.
With filters on two fields, the execution plan is still the same as in the first test.

When the query is changed to filter on all three fields, SQL Server can no longer obtain all necessary information from the filter, and the number of records satisfying the filtering criteria is high enough to make it switch from index seek with key lookup to clustered index scan.
In both cases the server sends the same number of records to the client, but the total execution time is significantly different now.
With two fields filtered, it takes a little over one second.
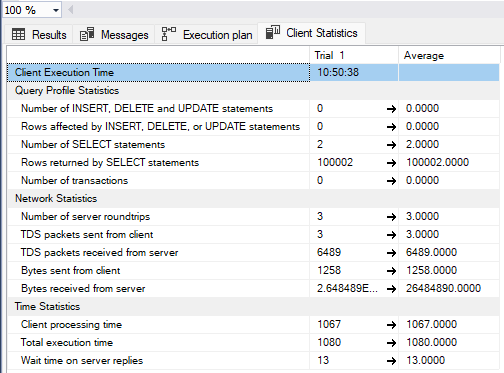
When the third filter is applied and the execution plan changes to table scan, the total time actually goes down to 423 milliseconds.
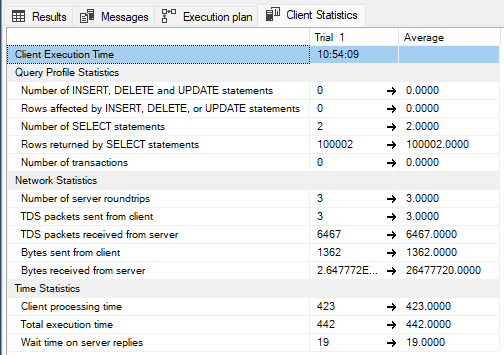
So as we can see here, table scan in the execution plan does not necessarily mean that this plan is worse than a seek with key lookup.
Test 3: Clustered data with a selective filter outside of the index
Still, test 2 is also an extreme case which is unlikely to be encountered in practice. Test 3 deals with a more practical scenario. Now I'm exploring queries on skewed data in columns 1 and 2, whilst keeping the uniform distribution for column 3. In this test, 10% of all rows have the same combination of Code Field 1 and Code Field 2, similarly to the Test 2, but with uniform Code Field 3. This is closer to the goal of this presumed optimisation.
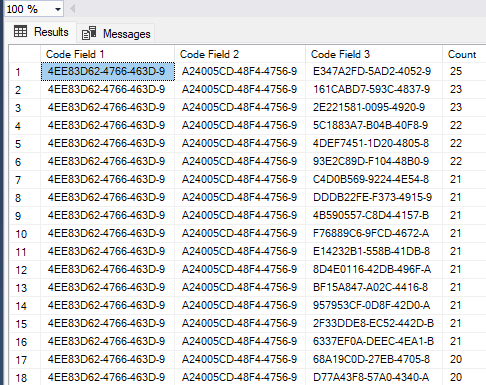
This distribution is more like what we expect to find in a real-life database and a good challenge for SQL Server query optimizer: a large cluster of records with identical values in the first two fields, but an additional filter on the third field, which is not a part of the index, limits the resulting set to just a handful of records.
Again, I run both queries - one with filters on 2 fields and the other filtering 3 fields - on this new dataset.
First, let's have a look at the execution plan for two filters.
Query optimizer suggests to create an index with included fields to dramatically decrease the execution time, but in the absence of this index, the best execution plan still involves an index seek supplemented by a key lookup.
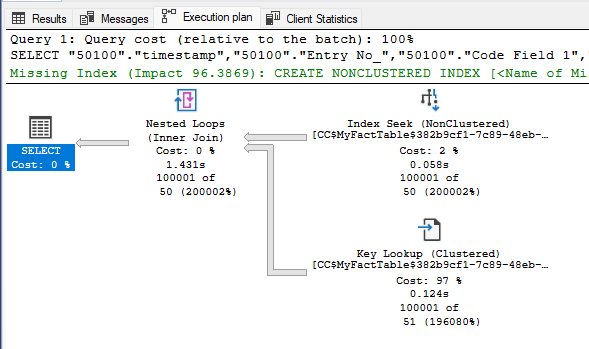
Similarly, for the 3-fields filter (partial index match) SQL Server once again suggests the non-clustered index seek instead of the clustered index scan which was preferred in the previous test.

The main difference with the two filters case is that the Key Lookup operation now returns only 23 rows.
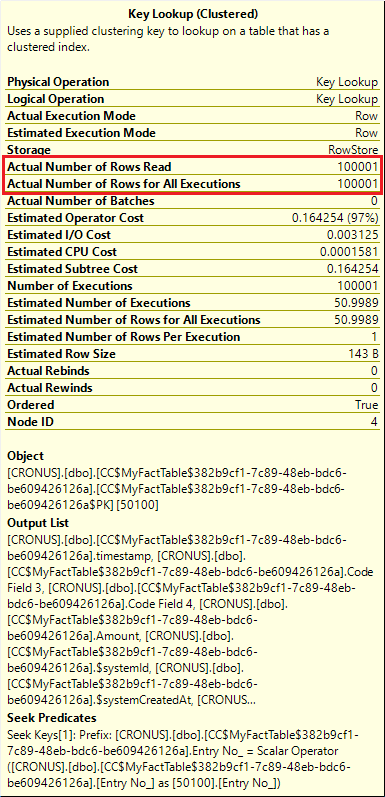
If we take a closer look at the operation details, we can see that the key lookup for two-fields case is executed without any predicates. It reads 100 000 rows and sends all of them to the query result - very much in line with the expectations.
With filters on three fields, on the other hand, a predicate is added to the key lookup operation and only 23 rows out of 100 000 make it to the query result.
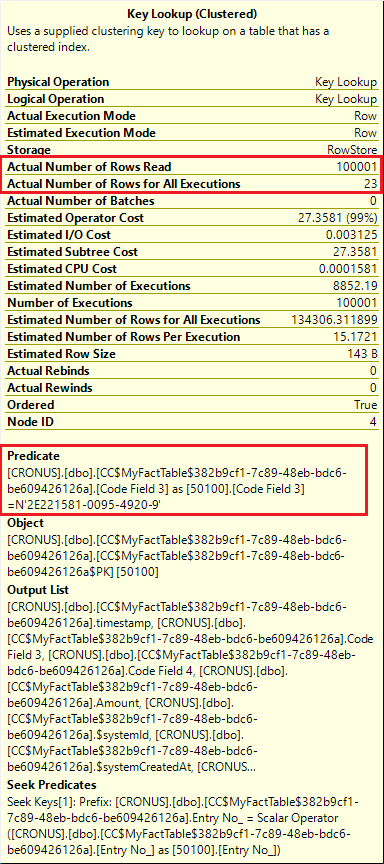
We can see that the key lookup operation now does all the heavy lifting filtering the rows with the required value in Code Field 3. This is the most expensive operation in both cases - with 2 filters or 3 filters, and all in all, the execution time remains more or less the same.
But let's take a look at the client statistics now.
This is how it worked out for two filters that match the index.
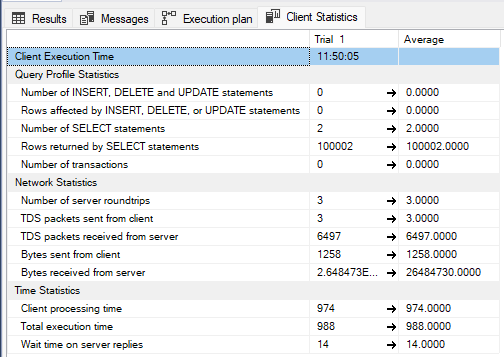
The large dataset that matches the broad filtering criteria is dumped to the client (SQL Server Management Studio in this case), so the client receives all 100 000 records that satisfy the filters on the first two fields, and these records amount to circa 26 MB of data sent over network.
Total execution time of the query is around 1 second, but thanks to the FAST 50 option and the fact that all retrieved rows are sent to the client without exceptions, the client does not have to wait for the server to complete the query and starts processing records just 14 ms after the query is triggered. Thanks to this, client and server processes are executed in parallel without much delay on the client.
How about the client statistics for the query with filters on all three fields?
Here, we see a significant increase in total processing time, despite the dramatic drop of the number of records received by the client.

Here, the client receives only 23 records, but shows 640 ms idle time waiting for the server to send any data, so the total time rises to 1471 ms, noticeably slower this time.
The reason behind this long wait is the data filtering added to server operations that I highlighted above. When filters are applied on two fields with the matching index, every key returned by the index seek satisfies all query predicates. Key lookup operation retrieves all requested fields without additional predicates. Server starts sending the data stream to the client almost immediately - with just 14 ms delay.
The second plan, on the other hand, rejects the majority of the table rows - only 23 out of 100 000 satisfy the last filter. Therefore, the server does not send any data to the client until the whole recordset (or the bulk of it) is processed.
So, looking at the numbers above, can we say that it is a good idea to leave filters on two fields only and push processing to the client side? Not yet. After all, we only measured the time it takes to retrieve records from the database and allocate it on the client, but did not take into account the time required to iterate over this dataset in Business Central to select the final subset of records.
Test 4: Measuring loop time in Business Central
This will be the simplest test of all - it only loops through all records in BC, counting the number of iterations and measuring the time.
This code snippet does the counting with two filters, applying a condition in AL code to skip records not matching the last filter value.
It takes 1768 ms to loop through all 100 000 records. Just to reiterate, this test is also executed with cold cache, restarting all services after each run.

And now the second run, this time applying all three filters in the query and iterating on the selected 23 records.
Run time goes down to 1334 ms. Not a dramatic improvement over the two filters case, but it's still faster, despite the client time statistics in SSMS showing otherwise.
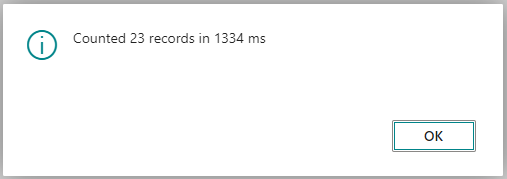
All because the allocation of a large number of records in Business Central and the loop on these records also takes its toll on the overall performance.
Conclusion
To conclude, the attempt to improve query performance by adjusting record filters in AL to match index fields does not look like a good idea. As we saw above, in some cases it can reduce client waiting time and increase the degree of parallelism between SQL Server and BC server because SQL Server can start pushing data to BC earlier, but this only means that a higher number of records will be sent over network, and BC server will be busy allocating and filtering the records which must be ignored. So all in all, this strategy leads to higher workload and more delays in server response time.
It's getting worse if the query is issued with UPDLOCK option - if, for example, LockTable is called on the table being queried, or the FindSet is invoked with ForUpdate argument as FindSet(true). we should remember that SQL Server places update lock on all records returned by the query, so loosening the filtering criteria results in more records being locked, increasing the risk of lock escalation.
Takeaway one: despite a common belief, an execution plan involving a clustered index scan is not necessarily worse than a plan based on a non-clustered index seek (some good reading, for example, here and here).
Takeaway two: any attempt to outsmart the SQL Server query optimizer must have a very good reason and usually a very specific dataset.



Comments